我们知道,计算机内部,所有信息最终都是一个二进制值。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从00000000到11111111。
字符编码是计算机技术的基石,想要熟练使用计算机,就必须懂得一点字符编码的知识。常见的字符编码方式有:ASCII、GB2312、GBK、GB18030、UTF8。 目前用的比较多的是GBK和UTF8(大多数网页采用的是UTF8编码,所以网页源码一般都有<meta charset="UTF-8">的标签)。
本文只讲字符编码。先通过字符编码的时间线,让大家对他们有个大体了解。然后具体说明一下每个编码出现的背景,原因,用途等。通过时间线的方法,也会帮忙你理解他们之间的关系。
以下是常见字符编码方法的时间线表示:
1963年:ASCII
1977年:Base64
1980年代初:GB2312
1984年:Big5
1987年:ISO-8859-1(Latin-1)
1991年:UTF-16
1992年:UTF-8
1995年:GBK(Guo Biao Kangxi)
1996年:UTF-32
2000年:GB18030
PS:
以下是这些字符集编码方法的比较:
| 字符集编码方法 | 特点 | 适用范围 |
|---|---|---|
| ASCII | 简单,兼容性好 | 英文文本 |
| Unicode | 通用,可以容纳世界上所有文字和符号 | 所有语言文本 |
| UTF-8 | 通用,兼容性好,是目前使用最广泛的字符编码方案 | 所有语言文本 |
| GB2312 | 简体中文 | 简体中文文本 |
| GBK | 简体中文,兼容GB2312 | 简体中文文本 |
| Big5 | 繁体中文 | 繁体中文文本 |
编码之间的兼容性如下图所示[1],国标GB编码和UTF8互相不兼容,这也就是为什么日常会看到文件的乱码:通过UTF8的编码方式打开国标GB编码的文件,或用国标GB的编码方式打开UTF8编码的文件。
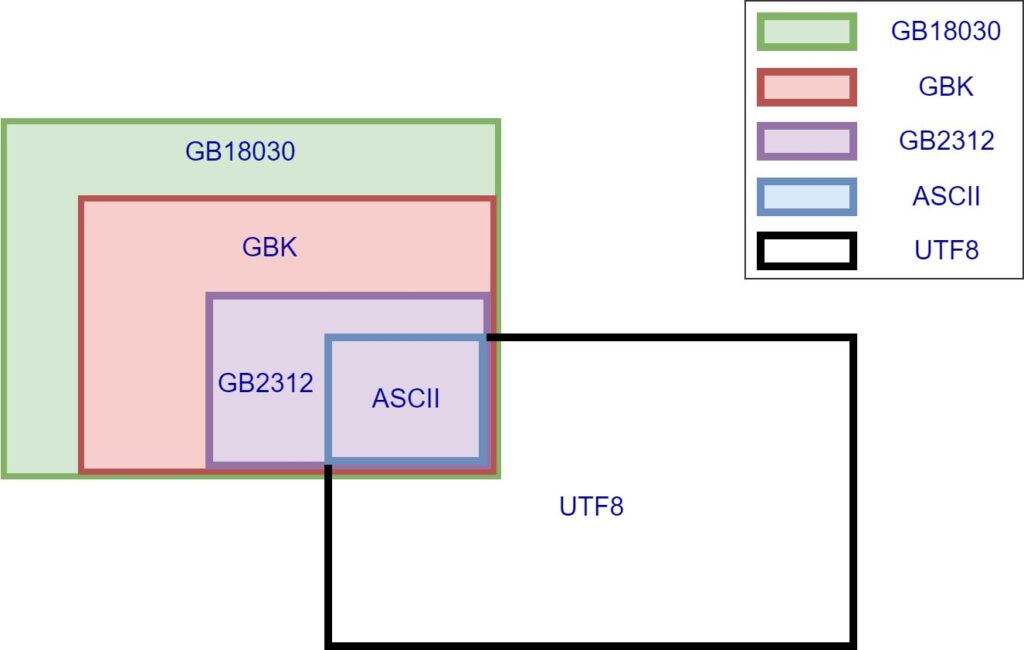
ASCII编码几乎被世界上所有编码所兼容,除了UTF16和UTF32编码[1]。
我想等网站访问量多了,在这个位置放个广告。网站纯公益,但是用爱发电服务器也要钱啊 ----------狂奔的小蜗牛